
We Tried and Tested the 9 Best Comet Alternatives for Model Evaluation
In this article, you will learn about the best Comet alternatives for model evaluation.

Feb 19, 202614 mins
9 posts with this tag
In this article, you will learn about the best Comet alternatives for model evaluation.


Explore 419 new real-world LLMOps case studies from the ZenML database, now totaling 1,182 production implementations—from multi-agent systems to RAG.

In this article, you will learn about the best DeepEval alternatives that you can use for LLM evaluation.

In this article, you learn about the best Langfuse alternatives for tracing, eval, prompt management, and metrics for LLM apps.

Discover the 9 best LLM evaluation tools to test your AI models before going live.
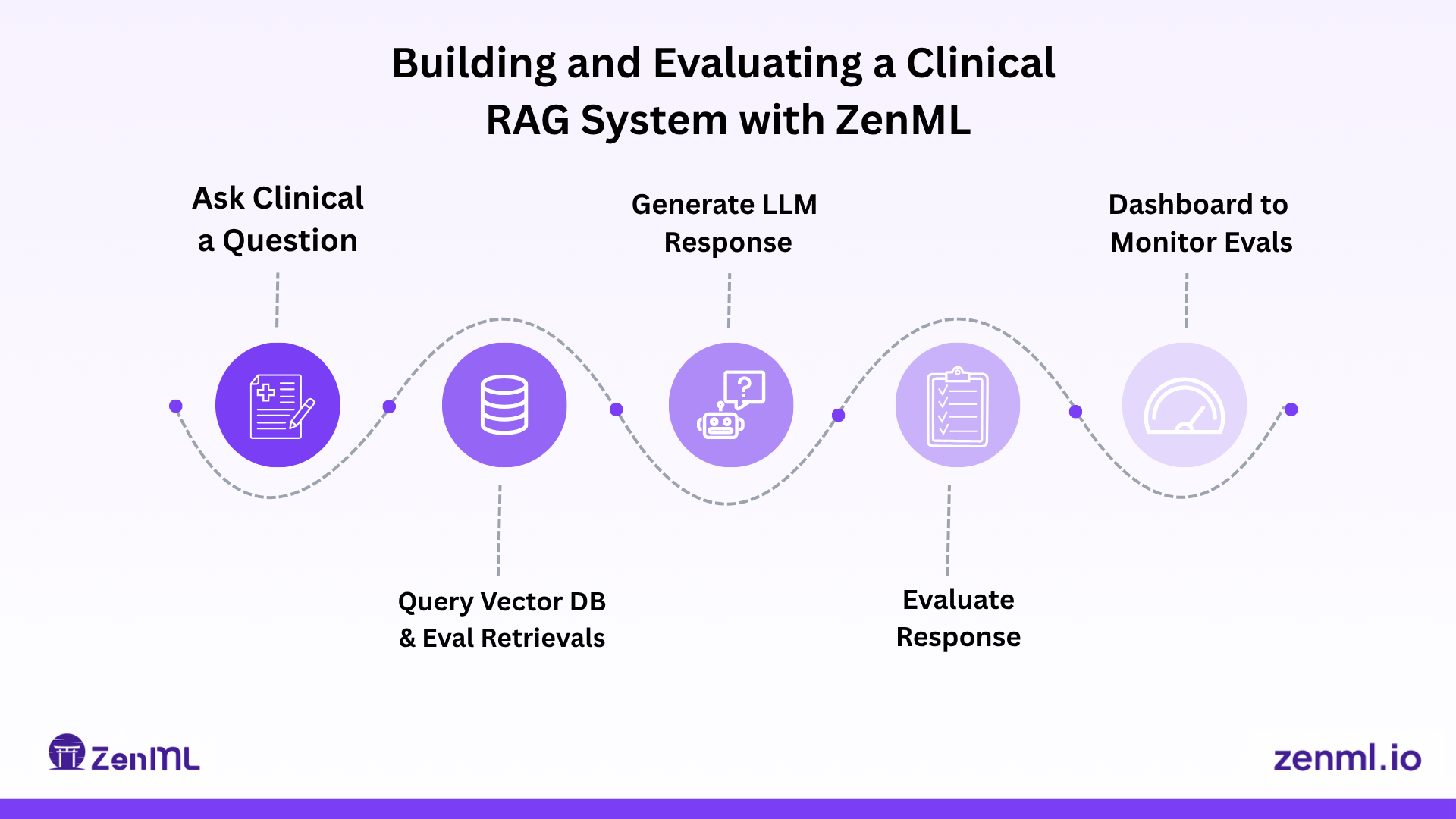
On custom evaluation frameworks for clinical RAG systems, showing why domain-specific metrics matter more than plug-and-play solutions when trust and safety are non-negotiable.

Lessons from the Maven Evals course are combined with 50+ real-world case studies from ZenML's LLMOps Database to show how companies like Discord, GitHub, and Coursera implement the Three Gulfs model and Analyze-Measure-Improve lifecycle to transform failing LLM systems into production-ready applications.

287 latest curated summaries of LLMOps use cases in industry, from tech to healthcare to finance and more. This blog also highlights some of the trends observed across the case studies.

