
The Hidden Complexity of ML Pipeline Schedules
ML pipeline scheduling hides complexity beneath simple cron syntax—lessons on freshness, monitoring gaps, and overrun policies from Twitter, LinkedIn, and Shopify.

Jan 23, 20267 mins
15 posts with this tag
ML pipeline scheduling hides complexity beneath simple cron syntax—lessons on freshness, monitoring gaps, and overrun policies from Twitter, LinkedIn, and Shopify.

Discover the top 8 Semantic Kernel alternatives that will help you build efficient AI agents.

In this Metaflow vs MLflow vs ZenML article, we explain the difference between the three platforms and educate you about using them in tandem.

Discover the top 10 Databricks alternatives designed to eliminate the pain points you might face when using Databricks. This article will walk you through these alternatives and educate you about what the platform is all about - features, pricing, pros, and cons.

This release incorporates updates to the SageMaker Orchestrator, DAG Visualizer, and environment variable handling. It also includes Kubernetes support for Skypilot and an updated Deepchecks integration. Various other improvements and bug fixes have been implemented across different areas of the platform.

ZenML's latest release 0.66.0 adds support for Python 3.12, removes some dependencies for a slimmer Client package and adds the ability to view all your pipeline runs in the dashboard.

ZenML's latest release 0.65.0 enhances MLOps workflows with single-step pipeline execution, AzureML SDK v2 integration, and dynamic model versioning. The update also introduces a new quickstart experience, improved logging, and better artifact handling. These features aim to streamline ML development, improve cloud integration, and boost efficiency for data science teams across local and cloud environments.

We dive deep into the world of Retrieval-Augmented Generation (RAG) pipelines and how ZenML can streamline your RAG workflows.

Transform quickstart PyTorch code as a ZenML pipeline and add experiment tracking and secrets manager component.

We built an end-to-end production-grade pipeline using ZenML for a customer churn model that can predict whether a customer will remain engaged with the company or not.

Use caches to save time in your training cycles, and potentially to save some money as well!

Why data scientists need to own their ML workflows in production.

Eliminate technical debt with iterative, reproducible pipelines.
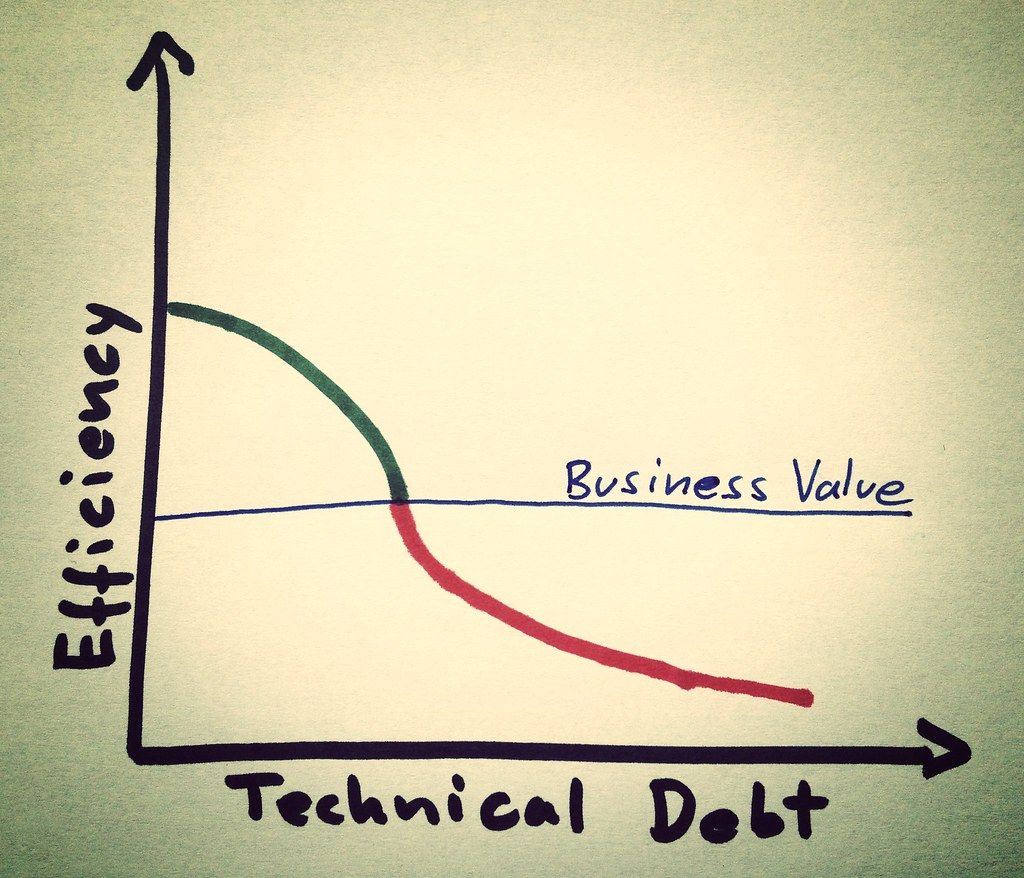
Pipelines help you think and act better when it comes to how you execute your machine learning training workflows.

ZenML makes it easy to setup training pipelines that give you all the benefits of cached steps.

