The Anatomy of a Production Coding Agent
A production coding agent isn't a prompt and a while loop. It's eight stages, each with different failure modes, costs, and human touchpoints. Here's the full pattern.

Mar 15, 2026
44 posts with this tag
A production coding agent isn't a prompt and a while loop. It's eight stages, each with different failure modes, costs, and human touchpoints. Here's the full pattern.


In this article, you will learn about the best DeepEval alternatives that you can use for LLM evaluation.

In this article, you learn about the best Langfuse alternatives for tracing, eval, prompt management, and metrics for LLM apps.

In this Smolagents vs LangGraph, we explain the difference between the two and conclude which one is the best to build AI agents.

Discover the best LLM observability tools currently on the market to build agentic AI workflows.
Discover the top 8 Langflow alternatives you can leverage to build and deploy AI agents.
Discover the 7 best Agentic AI frameworks to help you build smarter AI workflows this year.


In this LlamaIndex pricing guide, we discuss the costs, features, and value LlamaIndex provides to help you decide if it’s the right investment for your business.

In this CrewAI pricing guide, we discuss the costs, features, and value CrewAI provides to help you decide if it’s the right investment for your business.

In this Agentforce pricing guide, we discuss the costs, features, and value Agentforce provides to help you decide if it’s the right investment for your business.

Comprehensive analysis of why simple AI agent prototypes fail in production deployment, revealing the hidden complexities teams face when scaling from demos to enterprise-ready systems.

Lessons from the Maven Evals course are combined with 50+ real-world case studies from ZenML's LLMOps Database to show how companies like Discord, GitHub, and Coursera implement the Three Gulfs model and Analyze-Measure-Improve lifecycle to transform failing LLM systems into production-ready applications.

In this LlamaIndex vs LangGraph article, we explain the differences between these platforms and when to use each one for optimal results.

In this LangGraph vs CrewAI article, we explain the difference between the three platforms and educate you about using them efficiently inside ZenML.

Learn how to build production-ready agentic AI workflows that combine powerful research capabilities with enterprise-grade observability, reproducibility, and cost control using ZenML's structured approach to controlled autonomy.
Discover the new ZenML MCP Server that brings conversational AI to ML pipelines. Learn how this implementation of the Model Context Protocol allows natural language interaction with your infrastructure, enabling query capabilities, pipeline analytics, and run management through simple conversation. Explore current features, engineering decisions, and future roadmap for this timely addition to the rapidly evolving MCP ecosystem.
Learn how to build, fine-tune, and deploy multimodal LLMs using ZenML. Explore LLMOps best practices for deployment, real-time inference and model management.

Discover how ZenML implements the llms.txt standard to make ML documentation more accessible to both AI assistants and humans. Learn about our modular approach using specialized documentation files, practical integration with AI development tools, and how this structured format enhances the developer experience across different context window sizes.

A comprehensive overview of lessons learned from the world's largest database of LLMOps case studies (457 entries as of January 2025), examining how companies implement and deploy LLMs in production. Through nine thematic blog posts covering everything from RAG implementations to security concerns, this article synthesizes key patterns and anti-patterns in production GenAI deployments, offering practical insights for technical teams building LLM-powered applications.
Learn how leading companies like Dropbox, NVIDIA, and Slack tackle LLM security in production. This comprehensive guide covers practical strategies for preventing prompt injection, securing RAG systems, and implementing multi-layered defenses, based on real-world case studies from the LLMOps database. Discover battle-tested approaches to input validation, data privacy, and monitoring for building secure AI applications.

A comprehensive exploration of real-world lessons in LLM evaluation and quality assurance, examining how industry leaders tackle the challenges of assessing language models in production. Through diverse case studies, the post covers the transition from traditional ML evaluation, establishing clear metrics, combining automated and human evaluation strategies, and implementing continuous improvement cycles to ensure reliable LLM applications at scale.

Practical lessons on prompt engineering in production settings, drawn from real LLMOps case studies. It covers key aspects like designing structured prompts (demonstrated by Canva's incident review system), implementing iterative refinement processes (shown by Fiddler's documentation chatbot), optimizing prompts for scale and efficiency (exemplified by Assembled's test generation system), and building robust management infrastructure (as seen in Weights & Biases' versioning setup). Throughout these examples, the focus remains on systematic improvement through testing, human feedback, and error analysis, while balancing performance with operational costs and complexity.

Explore real-world applications of Retrieval Augmented Generation (RAG) through case studies from leading companies in the ZenML LLMOps Database. Learn how RAG enhances LLM applications with external knowledge sources, examining implementation strategies, challenges, and best practices for building more accurate and informed AI systems.

The LLMOps Database offers a curated collection of 300+ real-world generative AI implementations, providing technical teams with practical insights into successful LLM deployments. This searchable resource includes detailed case studies, architectural decisions, and AI-generated summaries of technical presentations to help bridge the gap between demos and production systems.

Explore key insights and patterns from 300+ real-world LLM deployments, revealing how companies are successfully implementing AI in production. This comprehensive analysis covers agent architectures, deployment strategies, data infrastructure, and technical challenges, drawing from ZenML's LLMOps Database to highlight practical solutions in areas like RAG, fine-tuning, cost optimization, and evaluation frameworks.

As organizations rush to adopt generative AI, several major tech companies have proposed maturity models to guide this journey. While these frameworks offer useful vocabulary for discussing organizational progress, they should be viewed as descriptive rather than prescriptive guides. Rather than rigidly following these models, organizations are better served by focusing on solving real problems while maintaining strong engineering practices, building on proven DevOps and MLOps principles while adapting to the unique challenges of GenAI implementation.

As Large Language Models (LLMs) revolutionize software development, the challenge of ensuring their reliable performance becomes increasingly crucial. This comprehensive guide explores the landscape of LLM evaluation, from specialized platforms like Langfuse and LangSmith to cloud provider solutions from AWS, Google Cloud, and Azure. Learn how to implement effective evaluation strategies, automate testing pipelines, and choose the right tools for your specific needs. Whether you're just starting with manual evaluations or ready to build sophisticated automated pipelines, discover how to gain confidence in your LLM applications through robust evaluation practices.

Machine Learning (ML) adoption is gaining momentum, but challenges include robust pipelines, quality issues, and scale monitoring. Recognizing and overcoming these challenges is crucial.
In the AI world, fine-tuning Large Language Models (LLMs) for specific tasks is becoming a critical competitive advantage. Combining Lightning AI Studios with ZenML can streamline and automate the LLM fine-tuning process, enabling rapid iteration and deployment of task-specific models. This approach allows for the creation and serving of multiple fine-tuned variants of a model, with minimal computational resources. However, scaling the process requires resource management, data preparation, hyperparameter optimization, version control, deployment and serving, and cost management. This blog post explores the growing complexity of LLM fine-tuning at scale and introduces a solution that combines the flexibility of Lightning Studios with the automation capabilities of ZenML.

The integration of ZenML and Databricks streamlines LLM development and deployment processes, offering scalability, reproducibility, efficiency, collaboration, and monitoring capabilities. This approach enables data scientists and ML engineers to focus on innovation.

ZenML's latest release 0.65.0 enhances MLOps workflows with single-step pipeline execution, AzureML SDK v2 integration, and dynamic model versioning. The update also introduces a new quickstart experience, improved logging, and better artifact handling. These features aim to streamline ML development, improve cloud integration, and boost efficiency for data science teams across local and cloud environments.
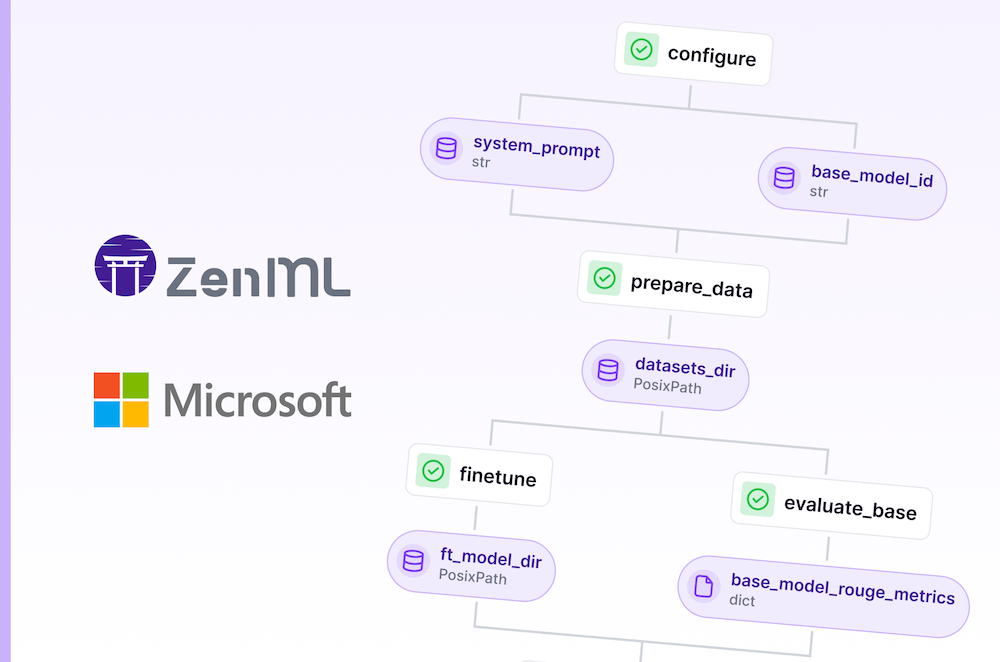
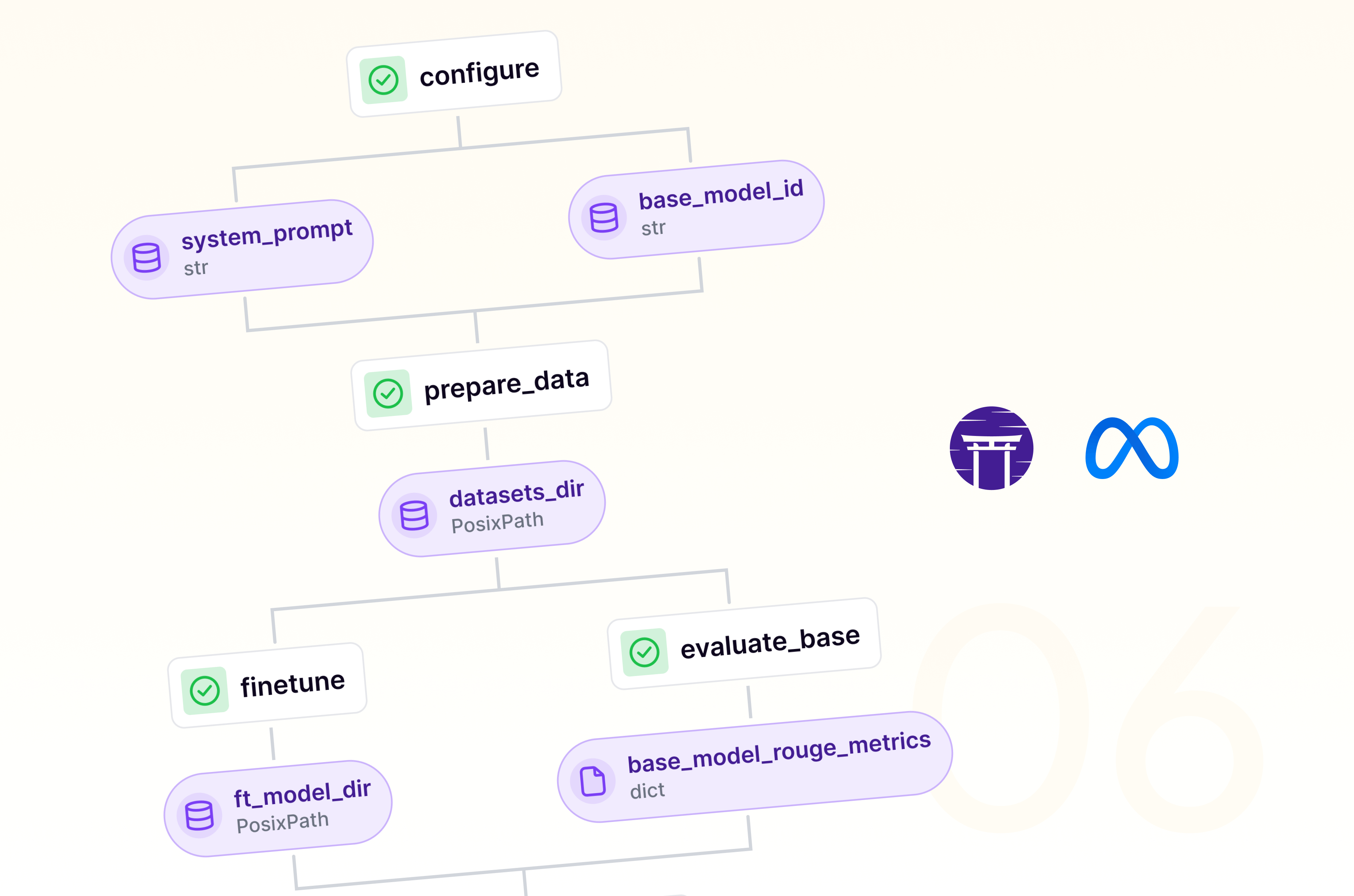
Master cloud-based LLM finetuning: Set up infrastructure, run pipelines, and manage experiments with ZenML's Model Control Plane for Microsoft's latest Phi model.
ZenML's new direction: Simplifying infrastructure connections for enhanced MLOps.

Master cloud-based LLM finetuning: Set up infrastructure, run pipelines, and manage experiments with ZenML's Model Control Plane for Meta's latest Llama model.
OpenAI's Batch API allows you to submit queries for 50% of what you'd normally pay. Not all their models work with the service, but in many use cases this will save you lots of money on your LLM inference, just so long as you're not building a chatbot!

Today, we're back to LLM land (Not too far from Lalaland). Not only do we have a new LoRA + Accelerate-powered finetuning pipeline for you, we're also hosting a RAG themed webinar.

Context windows in large language models are getting super big, which makes you wonder if Retrieval-Augmented Generation (RAG) systems will still be useful. But even with unlimited context windows, RAG systems are likely here to stay because they're simple, efficient, flexible, and easy to understand.

Taking large language models (LLMs) into production is no small task. It's a complex process, often misunderstood, and something we’d like to delve into today.

Explore how ZenML, an MLOps framework, can be used with large language models (LLMs) like GPT-4 to analyze and version data from databases like Supabase. In this case study, we examine the you-tldr.com website, showcasing ZenML pipelines asynchronously processing video data and generating summaries with GPT-4. Understand how to tackle large language model limitations by versioning data and comparing summaries to unlock your data's potential. Learn how this approach can be easily adapted to work with other databases and LLMs, providing flexibility and versatility for your specific needs.

We decided to explore how the emerging technologies around Large Language Models (LLMs) could seamlessly fit into ZenML's MLOps workflows and standards. We created and deployed a Slack bot to provide community support.



